post zaległy od wczoraj 🙂
w czasie projektowania i proponowania nowości do postgresa 8.2 padła idea by zacząć obsługiwać inserty wstawiające wiele rekordów. tak jak ma np. mysql:
INSERT INTO `tabele` (`pole1`, `pole2`) VALUES (1,1),(2,4),(2,7);
jak zawsze – panowie z core-teamu stwierdzili, że skoro robią już coś takiego, to może to trochę podkręcić.
wyszło z tego zupełnie nowe polecenie sql'owe: VALUES.
dzięki temu mogli zachować kompatybilność z standardowymi sql'ami, ale także wykorzystać to dla innych zastosowań.
zacznijmy od podstaw:
# CREATE TABLE x (id serial PRIMARY KEY, p_a TEXT, p_b TEXT); NOTICE: CREATE TABLE will create implicit sequence "x_id_seq" for serial column "x.id" NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "x_pkey" for table "x" CREATE TABLE # INSERT INTO x (p_a, p_b) VALUES ('standardowa', 'metoda'); INSERT 0 1 # INSERT INTO x (p_a, p_b) VALUES ('nowsza', 'metoda'), ('drugi', 'rekord'), ('następne', 'rekordy'); INSERT 0 3 # select * from x;
| id | p_a | p_b |
|---|
(4 rows)
fajne. tylko po co? no cóż. zrobiłem mały test. zrobiłem tabelkę:
# CREATE TABLE x (id serial PRIMARY KEY, liczba INT4);
i wstawiałem do niej dane (100000 kolejnych liczb) na kilka sposobów:
- copy x (liczba) from stdin;
- 100000 insertów – każdy po jednym rekordzie
- 100000 insertów – każdy po jednym rekordzie (ale z użyciem prepare i execute)
- 10000 insertów – każdy po dziesięć rekordów
- 10000 insertów – każdy po dziesięć rekordów (ale z użyciem prepare i execute)
- 5000 insertów – każdy po dwadzieścia rekordów
- 5000 insertów – każdy po dwadzieścia rekordów (ale z użyciem prepare i execute)
wyniki:
- copy: 0m1.045s
- insert (1): 1m5.473s
- insert + prepare (1): 1m3.483s
- insert (10): 0m8.500s
- insert + prepare (10): 0m7.552s
- insert (20): 0m4.065s
- insert + prepare (20): 0m3.656s
dla chętnych do powtórzenia testów/obejrzenia – skrypty oczywiście są dostępne.
graficznie wygląda to jeszcze bardziej interesująco:
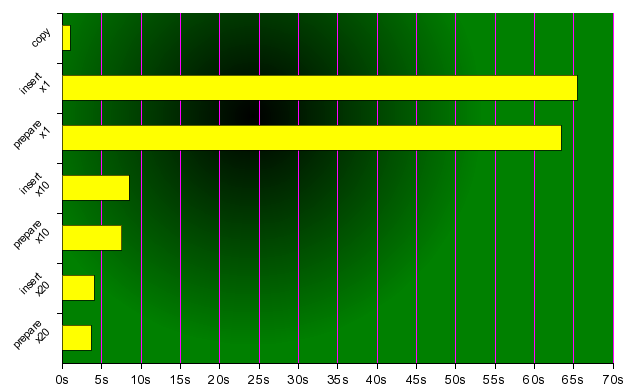 jak widac przyspieszenie insertów jest znaczne. czy to wszystko? nie!
jak widac przyspieszenie insertów jest znaczne. czy to wszystko? nie!
values można wykorzystać wszędzie tam gdzie potrzebujemy wielu rekordów. przykładowe zastosowanie – wyobraźmy sobie, że mamy pole typu int z zapisanymi statusami. statusów jest ledwie kilka. nie warto dla nich robić oddzielnej tabeli. ale jednak chcielibyśmy móc je w jakiś sposób odczytać z bazy … proszę:
# CREATE TABLE x (id serial PRIMARY KEY, liczba INT4); NOTICE: CREATE TABLE will create implicit sequence "x_id_seq" for serial column "x.id" NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "x_pkey" for table "x" CREATE TABLE # INSERT INTO x (liczba) VALUES (1), (2), (3), (2); INSERT 0 4 # SELECT x.id, x.liczba, k.kod FROM x join (VALUES (1, 'closed'), (2, 'new'), (3, 'open')) as k (id, kod) on x.liczba = k.id ;
| id | liczba | kod |
|---|
(4 rows)
oczywiście powyższy efekt można uzyskać używając (CASE WHEN … END), ale to rozwiązanie jest krótsze i mocno czytelniejsze.
zwracam też uwagę na to, że w oparciu o VALUES można zdefiniować widok:
# CREATE VIEW statusy AS SELECT * FROM (VALUES (1, 'closed'), (2, 'new'), (3, 'open')) as k (id, kod); CREATE VIEW # select * from statusy;
| id | kod |
|---|
(3 rows)
co jeszcze można z tym zrobić? sporo. pobawcie się sami i zastanówcie do czego można tego użyć.
values w selekcie jest wypasione, dzięki za pomysł!
Od dawna mamy analogiczną funkcjonalnośc 🙂
select 1,2
union all select 3,4
union all select 1,5
….
Chociaż tu pewnie z wydajnością sporo gorzej.