stawianie oracle'a jakoś nigdy nie było łatwe i proste. dziś przez przypadek trafiłem na stronę zawierającą linki do howto jak postawić oracle'a na różnych linuksach. różne wersje oracle'a. i nie tylko baza danych jako taka, ale także dodatki – rac, developer suite, application server.
muszę przyznać, że wygląda bardzo smakowicie 🙂
Author: depesz
nowa zabawka – c.d.
tak jak obiecałem – zrobiłem mocniejsze testy.
najpierw tylko takie info – jak pamiętacie poprzednio robiłem pgbencha -s 750. i na ustawieniach praktycznie “defaultowych" robił maksymalnie 830 tps. po dokonfigurowaniu robił (przy 100 połączeniach jednocześnie, czyli wtedy gdy poprzedni config robił 780-790) w zależności od nie wiem czego od 960 do 1070 tps'ów. całkiem ładnie.
potem zrobiłem bazę ze skalą pgbencha 7500. wielkość bazy – 120 giga, czas robienia pgbench -i – 150 minut.
ponieważ każdy test (każde concurrency) robię na czystej bazie, stwierdziłem, że robienie za każdym razem inicjalizacji po 150 minut odpada.
skopiowałem więc cały katalog $PGDATA na bok, i robiłem testy kopiując co test czysty katalog na miejsce “zużytego".
skrypt testujący:
#!/bin/bash -x<br /> export TOTAL_TRANS=1000000<br /> for C in 1 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 105 110 115 120 125 130 135 140 145 150 155 160 165 170 175 180 185 190 195 200<br /> do<br /> rm logs/* -f<br /> pg_ctl -w -l logs/x.log start<br /> TRANS=$[ $TOTAL_TRANS / $C ]<br /> pgbench -s 750 -c $C -t $TRANS -U pgdba -d bench 2> /dev/null > /home/pgdba/bench-$C.std<br /> pg_ctl -m immediate stop<br /> killall -9 postgres<br /> killall -9 postmaster<br /> killall -9 postgres<br /> killall -9 postmaster<br /> rm -rf /mnt/postgres/pgdba/data<br /> cp -a /mnt/postgres/pgdba/data.back /mnt/postgres/pgdba/data<br /> done
proste i miłe 🙂
wyniki wyglądają tak:
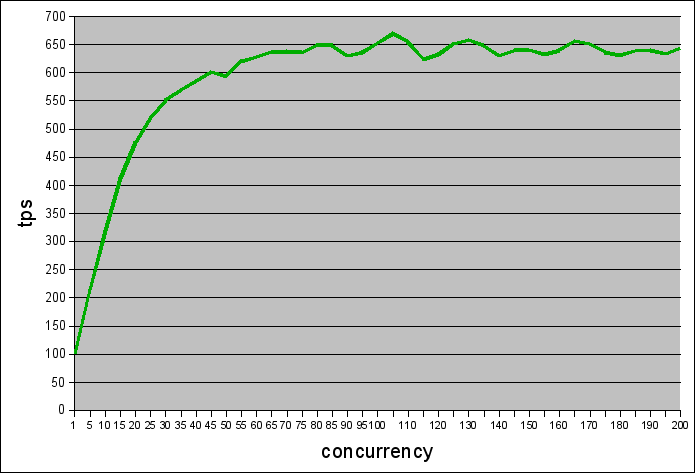
jest lepiej niż poprzednio – nie ma takiego spadku wydajności.
co interesujące – są skoki o amplitudzie około 50tps, ale wydaje mi się, że mogą one być spowodowane aktywnością poza-bazodanową (cron).
całość osięgnęła stabilną średnią około 640 tps. dla przypomnienia – przy wielkości bazy 4 razy większej niż ram. całkiem przyjemny wynik.
wybuchowe laptopy – ostatnie starcie
dell ogłosił największy recall (zna ktoś jakieś polskie określenie?) baterii – 4 miliony baterii idą do wymiany.
wymiana obejmuje baterie z tych modeli:
- Latitude: D410, D500, D505, D510, D520, D600, D610, D620, D800, D810
- Inspiron: 500M, 510M, 600M, 700M, 710M, 6000, 6400, 8500, 8600, 9100, 9200, 9300, 9400, E1505, E1705
- Precision: M20, M60, M70, M90
- XPS: XPS, XPS Gen2, XPS M170, XPS M1710
aby sprawdzić czy twoja bateria idzie do wymiany, obejrzyj naklejkę z numerem seryjnym baterii. znajdź na niej odpowiedni kod:
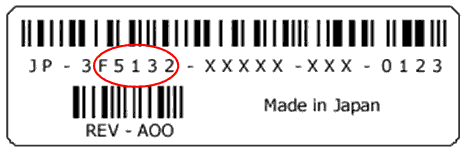
jeśli ten kod u ciebie to jeden z tych:
- 1K055
- 3K590
- 59474
- 6P922
- C2603
- C5339
- C5340
- C5446
- C6269
- C6270
- D2961
- D5555
- D6024
- D6025
- F2100
- F5132
- GD785
- H3191
- JD616
- JD617
- KD494
- M3006
- RD857
- TD349
- U5867
- U5882
- W5915
- X5308
- X5329
- X5332
- X5333
- X5875
- X5877
- Y1333
- Y4500
- Y5466
no to sprawdzaj szybciutko jak wymienić swoje “ognisko domowe" 🙂
sprzęt do testowania wydajności serwisów webowych
przez poniekąd przypadek trafiłem na stronę producenta interesującego rozwiązania sprzętowo/software'owego do testowania wydajności serwisów webowych.
możliwości wyglądają interesująco:
- symuluje od 50 do ponad 2 milionów jednoczesnych użytkowników, korzystających z różnych adresów ip!
- emuluje różne przeglądarki i różne “strategie" działania użytkowników
- sprawdza odporność przed wirusami i atakami ddos
- generuje gotowe, zintegrowane statystyki w postaci raportu eksportowalnego do np. pdf'a – którego można bezpośrednio już przekazać klientowi/szefowi.
eh. może mi ktoś kupi takie?
sprzętowa wirtualizacja wolna?
twórcy znanego oprogramowania wirtualizującego – vmware'a, opublikowali raport z którego wynika, że sprzętowa wirtualizacja jest często wolniejsza od software'owej!
raport wini za ten stan rzeczy fakt iż sprzętowa wirtualizacja musi używać “trapów" (pułapek?) aby wyłapać potencjalnie niebezpieczne operacje, podczas gdy software'owa wirtualizacja można użyć dużo “tańszego" sposobu – podmiany kodu.
muszę przyznać, że wynik mnie trochę zaskoczył – w końcu od zawsze rozwiązania hardware'owe były traktowane jako szybsze/lepsze.
przykładowy wynik testów jakie przeprowadzili – kompilacja kernela – bezpośrednio (bez wirtualizacji) trwała 263 sekundy. poprzez wirtualizację software'ową: 393 sekundy. poprzez wirtualizację “wspomaganą" sprzętowo – 484 sekundy!
jedno drobne ale – pozostaje kwestia czy można wierzyć vmware'owi w tym co mówi. w sumie są producentami softu wirtualizującego. choć z drugiej strony – ich soft będzie działał niezależnie od tego co jest szybsze…
hp supportuje debiana!
coś niesamowitego. hp – taka firma od drukarek i serwerów ;-P, stwierdziło, że spora część ich klientów chce używać debiana (zamiast redhata i suse, do których support już oferowali) i dlatego supportują teraz też instalację i konfigurację debiana na swoich serwerach – przez cały okres gwarancyjny!
na razie support będzie do sarge'a, ale podobno od końca roku ma być też dla etcha.
oczywiście jak jest miód, to musi też być dziegć.
support nie będzie na tym samym poziomie co do redhata i suse. nie będzie (na razie) certyfikacji, że hp z debianem działa. support nie będzie reklamowany, a klienci sami będą musieli pościągać toole hp.
tym niemniej traktuję to jako objaw mocno pozytywny. wreszcie będę miał się do kogo zwrócić gdy np. mi kernel będzie sypał co 30 minut panicami na dl 380 🙂
poglądy polityczne
wszedłem dziś przypadkiem na blog wo, i znalazłem tam informacje o quizie politycznym który pokazuje gdzie na dwuwymiarowej siatce poglądów się znajduję.
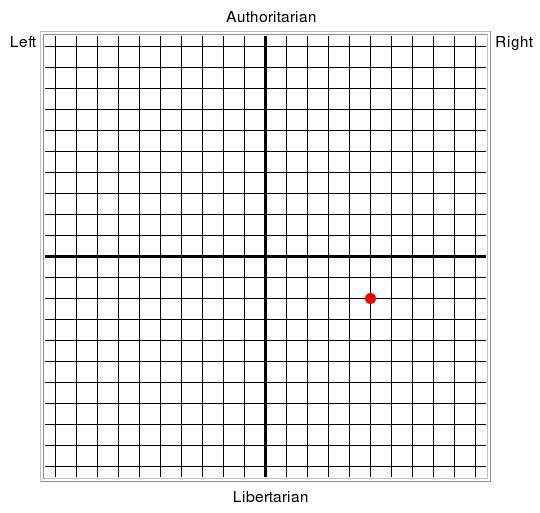
test zrobiłem. i co mi wyszło?
Economic Left/Right: 5.13
Social Libertarian/Authoritarian: -1.59
wykres wyglądał mi tak:
jest to interesujące z dosyć śmiesznego powodu. na stronie jest mapka poglądów znanych polityków:
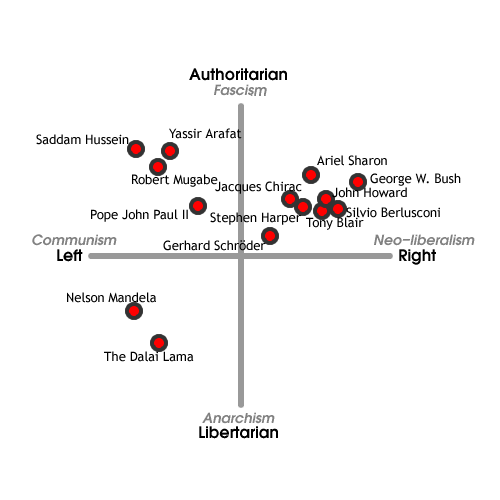
zwróciliście uwagę? nie ma nikogo w “mojej" ćwiartce. czyli jako polityk byłbym bezkonkurencyjny!
depesz na prezydenta!!!
nowa “zabawka”
jeden z klientów eo, firmy gdzie pracuję, właśnie kupił nowy serwer pod bazy danych. ponieważ maszynkę trzeba przetestować, stwierdziłem, że przy okazji porównam sobie jej wydajność z innym serwerem – nieużywanym już starszym serwerem bazodanowym.
poprzednia maszynka:
- 2 procesory amd opteron 250, 2.4ghz
- 4 giga ramu
- 4 dyski scsi, 15krpm, spięte sprzętowym raidem w dwie macierze raid1 po dwa dyski.
- postawiona pod centosem z kernelem 2.6.9-22.ELsmp
czyli tak naprawdę bez przesadnych rewelacji.
testowałem przy pomocy takiego skryptu:
#!/bin/bash export TOTAL_TRANS=1000000 for C in 1 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 do pg_ctl -w -l logs/x.log start dropdb bench createdb bench pgbench -i -s 750 -U pgdba -d bench TRANS=$[ $TOTAL_TRANS / $C ] pgbench -s 750 -c $C -t $TRANS -U pgdba -d bench 2> /dev/null > /home/pgdba/bench-$CC-$C.std pg_ctl -m immediate stop killall -9 postgres killall -9 postmaster killall -9 postgres killall -9 postmaster done
proste i konkretne. baza bench ma około 13 giga (aha. gdybyście chcieli powtórzyć test u siebie – pgbench się wywala na -s 750 (na niższych trochę pewnie też) i trzeba go zapatchować – w pgbench.c znaleźć polecenia tworzenia tabel i zastąpić inty bigintami.
postgresql'a użyłem 8.1.4, postgresql.conf zawierał wartości domyślne, zmieniłem jedynie 2 parametry:
max_connections = 110 shared_buffers = 65536 lc_messages = 'en_US.UTF-8' lc_monetary = 'en_US.UTF-8' lc_numeric = 'en_US.UTF-8' lc_time = 'en_US.UTF-8'
czyli jak widać nic specjalnego – chodziło mi nie o tuning postgresa, tylko o sprawdzenie o ile mi mniej więcej przyspieszy system po zmianie sprzętu.
wyniki starszego serwera:
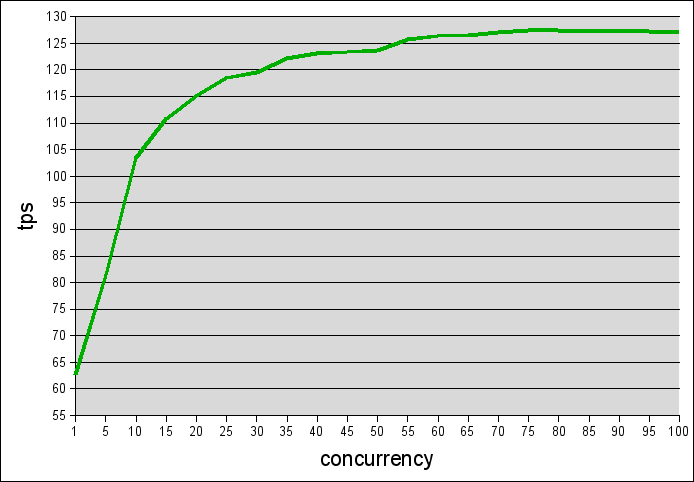
rzuca się w oczy stabilność wydajności przy przyroście jednocześnie połączonych klientów.
nowa maszynka:
- 4 procesory amd opteron 875, 2.2ghz
- 32 giga ramu
- 2 dyski sas na system, 14 dysków w zewnętrzen macierzy scsi, 15krpm, spięte w jedną dużą macierz raid10
- postawiona pod debinanem testing z kernelem 2.6.16-2-amd64-k8-smp
test i konfiguracja postgresa – identyczne.
wyniki:
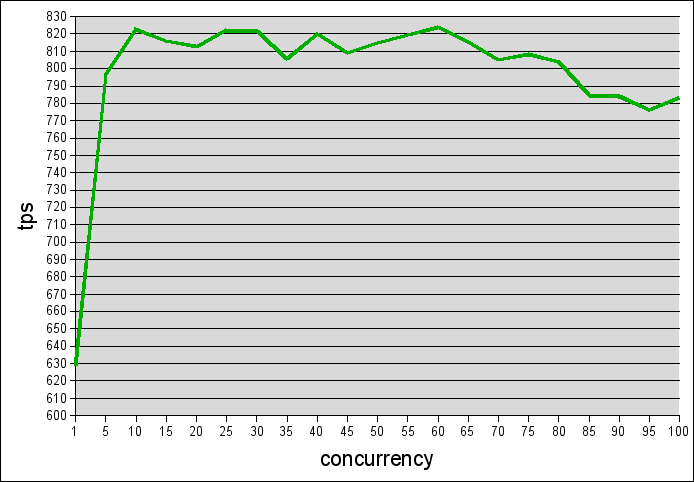
tym razem rzuca się w oczy brak stabilności wyników przy większej ilości połączeń.
ale też liczby są sporo wyższe 🙂 ponad 6 krotnie wyższe.
zakładam, że brak stabilności może wynikać z tego, że dla tej maszyny ta baza była mała. tzn. baza mająca 13 giga dla maszyny z 4giga ramu to sporo. ale dla maszyny z 32 giga ramu, to drobiazg.
zrobię jeszcze jeden test (będzie dłuższy, więc wyniki pewnie dopiero w poniedziałek) – dokonfiguruję postgresa do końca, i zrobię test na bazie danych tak ze 110 – 120 giga. postaram się zrobić testy do większej ilości klientów.
może to wyjaśni przyczynę dziwnych wahań wyników.
aha – testy nie są idealne – pgbench ma swoje standardowe problemy. dodatkowo – ta maszyna, co prawda nie jest używana normalnie, ale chodzi na niej cron który np. w nocy włącza “updatedb" to pewnie trochę zaburza wyniki.
jeszcze tylko muszę się dowiedzieć ile te maszynki kosztowały aby móc porównać “bang-for-bucks" 🙂
wkurzające konsekwencje udaremnionych zamachów
british airways, na fali obostrzeń po ostatnich (nieudanych) zamachach, zdecydowało się zakazać posiadania w samolocie kolejnych rzeczy:
- jakiejkolwiek elektroniki w tym notebooków czy palmtopów oraz breloczków elektronicznych do kluczy
- płynów (poza niezbędnymi lekarstwami, których brak mógłby zagrozić zdrowiu właściciela).
i to mnie osobiście boli.
jak gdzieś leciałem to zawsze miałem ze sobą lapa by móc coś poczytać/popisać, no i oczywiście butelkę coli – ilości które podają w samolocie, są może i wystarczające dla standardowych pasażerów, ale jak ktoś jest uzależniony od coli to bez 2 litrów się nie obejdzie.
oczywiście – można zamiast lapa wziąśc książkę. a i bez coli pewnie da się wytrzymać. ale wydaje mi się, że obostrzenia idą w złym kierunku.
nie mam nic przeciwko fotografowaniu ludzi na lotniskach i porównywaniu z bazami danych terrorystów. nie mam nic przeciwko kontrolom itd. ale pozbawianie mnie możliwości pracowania czy chociażby zabawy w trakcie długiego lotu – no to już jest przesada.
routing w linuksie
miałem ostatnio interesującą sytuację w firmie.
jeden z pracowników miał na swoim komputerze wersję demo nowego serwisu www. i trzeba było wystawić to dla klienta na zewnątrz.
teoretycznie trywiał – jak się okazało, nie do końca.
najpierw ogólnie.
sieć wygląda w uproszczeniu tak:
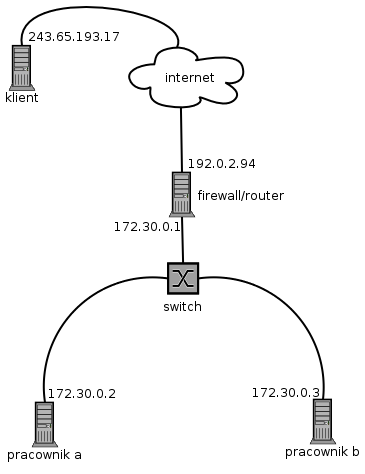
aplikacja była odpalona na komputerze “pracownik a".
na firewallu/routerze regułki były skomplikowane, ale dla uproszczenia przyjmijmy, że było tylko:
iptables -P INPUT DROP<br /> iptables -P FORWARD DROP<br /> iptables -F<br /> iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT<br /> iptables -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT<br /> iptables -A INPUT -p icmp -j ACCEPT<br /> iptables -A FORWARD -p icmp -j ACCEPT<br /> iptables -A INPUT -i lo -j ACCEPT<br /> iptables -A FORWARD -i lo -j ACCEPT<br /> iptables -A FORWARD -i eth0 -o eth1 -j ACCEPT # eth0 to sieć lokalna, eth1 - internet<br /> iptables -t nat -A POSTROUTING -o eth1 -j MASQUERADE
jak widać nic skomplikowanego.
no więc pojawia się zadanie – klient ma mieć wystawiony serwis z “pracownik a" (port 80) na dowolnym porcie.
ok. robimy:
iptables -t nat -A PREROUTING -s 243.65.193.17 -p tcp --dport 82 -j DNAT --to-destination 172.30.0.2:80
i … działa. zero zdziwień. proste i miłe.
ale jak wyżej napisałem – trywiał, ale nie do końca. jaki więc haczyk?
no cóż. następnego dnia pojawił się drugi request:
tak jak klient wchodzi na http://192.0.2.94:82/ to pracownicy z sieci (np. pracownik b) też mają móc.
i tu zaczęły się schody.
pierwszy strzał:
iptables -t nat -A PREROUTING -s 172.30.0.0/24 -d 192.0.2.94 -p tcp --dport 82 -j DNAT --to-destination 172.30.0.2:80<br /> iptables -A FORWARD -i eth0 -o eth0 -j ACCEPT
i nie działa.
chwila zastanowienia – nic prostego się nie okazuje.
tak więc rozrysowaliśmy sobie sytuację:
- “pracownik b" wysyła pakiet do 192.0.2.94:82. adres źródłowy pakietu: 172.30.0.3:1031 (jakiś losowy, wysoki port)
- ponieważ pakiet jest do innej sieci niż 172.30.0.0/24, zostaje przekazany do routera
- router ma regułkę która pakiet dnatuje, więc dane pakietu zmieniają się na:
źródło: 172.30.0.3:1031, cel: 172.30.0.2:80 - pakiet przechodzi przez firewalla zaakceptowany i wchodzi z powrotem do lanu.
- pakiet trafia do komputera “pracownik a". super! ale tu zaczynają się kłopoty.
- “pracownik a" odpowiada. zamienia miejscami nadawcę i odbiorcę pakietu, otrzymując:
źródło: 172.30.0.2:80, cel: 172.30.0.3:1031 - ponieważ cel jest w sieci 172.30.0.0/24 – wysyła pakiet bezpośrednio do odbiorcy – z pominięciem routera.
- do komputera “pracownik b" trafia pakiet (ack/syn), na dobry port, ale od złego ip?! “pracownik b" chciał “rozmawiać" z 192.0.2.94:82, a tu dostaje pakiet od 172.30.0.2:80 – czyli jakaś pomyłka. pakiet zostaje olany.
- nie bangla.
po rozrysowaniu sprawa stała się jasna.
pozostaje naprawić. pojawił się pomysł by robić DNAT'a, na “pracownik a" (przekazując pakiet do routera), ale to było brzydkie.
co finalnie zrobiliśmy?
na routerze dodaliśmy jedną regułkę:
iptables -t nat -A POSTROUTING -s 172.30.0.0/24 -d 172.30.0.2 -p tcp --dport 80 -j SNAT --to-source 172.30.0.1
i działa!
pełny przesył wygląda teraz tak:
- “pracownik b" wysyła pakiet do 192.0.2.94:82. adres źródłowy pakietu: 172.30.0.3:1031 (jakiś losowy, wysoki port)
- ponieważ pakiet jest do innej sieci niż 172.30.0.0/24, zostaje przekazany do routera
- router ma regułkę która pakiet dnatuje, więc dane pakietu zmieniają się na:
źródło: 172.30.0.3:1031, cel: 172.30.0.2:80 - pakiet przechodzi przez firewalla zaakceptowany
- przed wyjściem do lanu pakiej jest snatowany, więc dane pakietu zmieniają się na:
źródło: 172.30.0.1:1031, cel: 172.30.0.2:80 - pakiet trafia do komputera “pracownik a".
- “pracownik a" odpowiada. zamienia miejscami nadawcę i odbiorcę pakietu, otrzymując:
źródło: 172.30.0.2:80, cel: 172.30.0.1:1031 - ponieważ cel jest w sieci 172.30.0.0/24 – wysyła pakiet bezpośrednio do odbiorcy – ale w tym przypadku odbiorcą jest router
- mechanizm conntracka na routerze dokonuje odpowiednich (odwrotnych) translacji adresów, tak, że pakiet powrotny przyjmuje postać:
źródło: 192.0.2.94:82, cel: 172.30.0.3:1031 - do komputera “pracownik b" trafia pakiet (ack/syn), na dobry port, i od słusznego ip.
- bangla.
po zapisaniu tego wszystkiego sprawa staje się jasna i oczywista. ale nie zmienia to faktu, że kilka razy słychać było – “nie da się".
powyższy pomysł/regułki dedykuję wszystkim zdającym test na pracownika do nas 🙂 tam jest mocno podobne pytanie 🙂