jak może zauważyliście co jakiś czas robię sesję zdjęciową nt. gotowania.
jakiś czas temu zauwazyłem, że wszystkie książki z przepisami są pisane dla ludzi którzy już umieją gotować. po prostu takie przypominajki. o dużej ilości rzeczy nie mówią, lub traktuja jako oczywiste i warte tylko jednego słowa.
stąd wzięła się wizja fotografowania (nie mam kamery, bo jakbym miał to bym kręcił filmiki).
dziś trafiłem na stronę videojug. zawiera ona filmy pokazujące różne rzeczy które można robić w życiu. nie tylko gotowanie. zajmowanie się zwierzakami, majsterkowanie, sporty, maseczki pielęgnacyjne itd.
ale to część kuchenna mnie zauroczyła.
każdy przepis jest sfilmowany. bez udziału aktorów – po prostu pokazują co i jak się dodaje, jak się miesza, ile czasu. co trzeba mieć. filmy są po angielsku co może lekko utrudniać (ktoś wie czemu w przepisie na jambalayę mówią "green pepper" a pokazują coś co wygląda jak poszatkowana zielona papryka?).
ale poza tym – cód, miód i orzeszki. są przepisy na praktycznie każdy rodzaj żarcia. od zup, przez dania główne, desery aż po takie ciekawostki jak sałatka "coleslaw" znana choćby z kfc.
Author: depesz
idę popływać na basen
pływaliście kiedyś na basenie? 25 metrów długości, głębokość od 1.2 do 1.8 metra. to taki standard. a jakbym chciał coś więcej?
w belgii otwarto (chyba niedawno) interesujący basen. nazywa się nemo33.
cechy?
- głębokość do 33 metrów (basen nie jest sześcienny, więc głębokość jest mocno zmienna).
- 2.5 miliona litrów wody podgrzanej do około 30°c. niechlorowana!. widoczność ponad 33 metry (tzn. widać dno)
- 2 baseny, w nich 3 "dziury": 5, 10 i 33 metrowe
- "jaskinie" na głębokości 10 metrów. możliwość instalacji innych dekoracji gdyby była potrzeba.
- stałe podwodne dzwony z powietrzem – w celu ułatwienia powrotu (wynurzanie z 33 metrów wymaga powolnej dekompresji).
czad. a jak to wygląda?









sprzęt pod linuksa
dowiedziałem się przypadkiem o firmie "system76". jest ona podobno jednym z największych "supporter'ów" (nie mam pojęcia jak to przetłumaczyć by zachować sens) ubuntu. a co robi? sprzęt. pecety. i laptopy. bez windowsów, za to z linuksem.
jeśli kiedyś stawialiście linuksa na lapie wiecie, że nie jest słodko. hibernate, suspend, grafika, dźwięk, apm/acpi. wszystko to generuje problemy.
ale nie na sprzęcie system76!.
oni budują i konfigurują wszystko od podstaw tak by śmigało i nie generowało problemów.
a do tego – specyfikacje są naprawdę niezłe (nie będę cytował bo to i tak trzeba zobaczyć, a przecież nie zrobię kopii całego site'u).
co ciekawe – we wzornictwie widać ewidentne wpływy apple'a. w szczególności w modelu koala (desktop, wyglądający mniej więcej jak macmini).
dodatkowo – dowiedziałem się, że za mniej więcej 2 tygodnie ma wejść do sprzedaży nowy model lapa. specyfikacje:
- waga – trochę ponad 4 funty (1.8 kilograma)
- 3.5 cm grubości w najgrubszym miejscu
- wyświetlacz 13"
- 5 godzin pracy na baterii, więcej przy wyłączonym bluetoothu i wifi, oraz z włączonym skalowaniem cpu
parametry tego co kupił przedpremierowo pewien koleś:
- procesor: core 2 duo 2.0ghz
- ram: 1.5gb
- dysk: 60gb (7200rpm)
- wifi: 802.11 a/b/g
- bluetooth
- czytnik kart sd
- grafika: intel 945.
cena – w okolicach $1000.
czad. jeśli czyta to moje szefostwo: chciałbym poprosić o takie cudo zamiast della 🙂 nawet zniosę gnome'a. albo doinstaluję kde.
bilion dolarów
bilion. nie miliard. bilion. milion milionów. tysiąc miliardów. dolarów.
książka o pieniądzach.
opisy w sieci:
- Wielki bestseller w Europie Zachodniej, za sensacyjną opowieścią, trzymającą w napięciu od pierwszej do ostatniej strony, kryje się historia pieniądza i tego, jak niczego nie produkując można zostać Krezusem. Kapitalna książka dla maklerów giełdowych, miłośników sensacji i tajemnic.
Oto rozwoziciel pizzy staje się dziedzicem niewyobrażalnego wprost majątku, zapoczątkowanego przed 500 laty przez jego przodka, który miał wizję, którą teraz tenże rozwoziciel pizz ma zrealizować. -
To będzie hit końca 2006 roku, długo oczekiwana powieść sensacyjna, z elementami fantastyki, Andreasa Eschbacha, autora niezapomnianych "Gobeliniarzy" i "Wideo z Jezusem". Grubaśny tom będzie przypominał paczkę banknotów, bo jest to powieść o pieniądzu – tym najbardziej chyba pożądanym wynalazku człowieka, towarze wymiennym. Jest to powieść o tym, jak pieniądz rodzi nowy pieniądz, a mądrze inwestowany tworzy fortuny.
Książka dla miłośników fantastyki, amatorów dobrej powieści sensacyjnej, a także dla… maklerów giełdowych. - Bilion to milion milionów, tysiąc miliardów tyle dziedziczy w wyniku inwestycji zapoczątkowanej pięćset lat temu, w 1495 roku, przez swego przodka, skromny i fajtłapowaty John Fontanelli. Z dnia na dzień staje się krezusem, bogatszym niż 200 Gatesów razem wziętych. Od jego decyzji może zależeć los gospodarki świata, być albo nie być rządów i życie miliardów ludzi.
a co tak naprawdę w środku? dosyć przyjemne czytadło. z kilkoma "pradoksami" związanymi z ekologią, biedą i życiem. plus rozczarowująca końcówka.
książka przyjemna do poczytania jak ma się więcej czasu – na wakacjach, w podróży pociągiem.
książka przyjemna do poczytania jak ma się więcej czasu – na wakacjach, w podróży pociągiem.
z jednym "drobnym" ale.
nie wiem czy w oryginale też tak było, ale albo jest to wysoce "oryginalny" pomysł twórczy, albo polskie wydawnictwo solaris ma problemy z ludźmi od składu.
czytanie mocno utrudnia fakt iż nie ma żadnych przerw między akapitami dotyczącymi innych wątków. niby bzdurka. ale wielokrotnie zmuszała mnie do wracania do przeczytanego tekstu i czytania go jeszcze raz, bo dopiero na następnej stronie jest jakaś wzmianka o tym, że to co czytam tyczy się już innego wątku.
ogólnie skład jest jakiś taki "na chybcika". wydaje się, że książkę złożono i wydrukowane w 2 dni pod presją czasu aby zdążyć na choinkę.
na koniec – jedziesz na wakacje? jedziesz gdzieś daleko pociągiem? samolotem? kup. poczytasz, spodoba się. w innym przypadku – można sobie odpuścić.
odpowiedzialność za niebezpieczny kod
czy programista (albo firma programistyczna) powinna być odpowiedzialna za dziury w bezpieczeństwie jego (jej) produktu?
większość pewnie powie: oczywiście. tak.
ale nie wszyscy. alan cox – jeden z bardziej znanych guru linuksowych, współtwórca jądra, i ogólnie jeden z największych propagatorów linuksa. otóż on powiedział ostatnio, że uważa, że programistów/firm nie powinno się obciążać odpowiedzialnością za błędy bezpieczeństwa.
oczywiste jest to, że programiści mają moralny (etyczny) obowiązek tworzenia kodu tak bezpiecznego jak to tylko możliwe, ale nie można pociągać ich do odpowiedzialności gdy nastąpi włamanie/naruszenie reguł bezpieczeństwa.
czemu?
bo żyjemy w takim a nie innym świecie. wprowadzenie tego typu odpowiedzialności momentalnie wpłynęłoby (negatywnie) na rozszerzalność produktów – w końcu spora część błędów jest na granicach interakcji produktu z dodatkiem – np. przeglądarki z pluginem.
dodatkowo – byłoby to nieuczciwe, gdyż technologicznie nie da się wyciągnąć konsekwencji wobec twórców oprogramowania darmowego – jego rozwój jest zdecentralizowany, odpowiedzialność dzielona. w dodatku – o tak powstałe oprogramowanie oparte zostają inne platformy – np. komercyjne wersje dystrybucji linuksa, czy jakiekolwiek inne komercyjne pakiety.
wypowiedź alana skomentował jerry fishenden, zgadzając się z nim w zupełności. użył też interesującej metafory: nikt nie pozywa do sądu producenta zamków gdy włamywacz go (zamek) sobie otworzy i włamie sie do domu. czemu więc w przypadku oprogramowania odpowiedzialność ma być przeniesiona częściowo lub całkowicie na wytwórcę?
hmm … interesujący punkt widzenia. muszę się zastanowić co o tym sądzę, ale muszę przyznać, że ma to spory sens.
przełom w technologiach optycznych
naukowcom z uniwersytetu rochester udało się coś niesamowitego. spowolnili foton, (pojedynczy!), zapisali na nim obrazek, po czym odczytali ten obrazek z powrotem.
jest to niesamowite osiągnięcie, gdyż pokazuje kilka rzeczy:
- na pojedynczym fotonie można zapisać dużo informacji
- potrafimy zapisywać i odczytywać dane z fotonów
- przekroczyliśmy kolejny próg który oddzielał nas (ludzi) od stworzenia optycznych nośników informacji.
ostatnia częśc – optyczne nośniki informacji – jest niesamowita. jeśli na pojedynczym fotonie udało się tyle, to jaka będzie gęstość zapisu w produkcyjnych "dyskach"?
obrazek który zapisano nie był jakoś bardzo wysublimowany – ot 2 litery (symbol "university of rochester"). w dodatku – obrazek odtworzył się z pewnymi przekłamaniami.
ale tego typu przekłamania to żaden problem dla mechanizmów kontroli danych.
tak wyglądały obrazki zapisany i odczytany: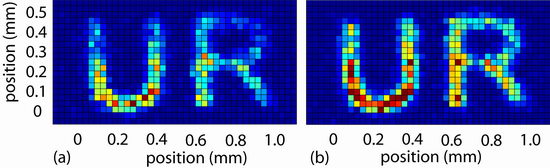
tapeta na dzis

zaśmiecony template1 i kopiowanie baz
standardowa instalacja postgresa zawiera 2 (lub 3) bazy:
- template0
- template1
- postgres (tylko w najnowszych wersjach)
template0 jest bezpieczna, o tyle, że nie da się do niej prosto podłączyć, więc nikt w niej nie namiesza.
baza template1 jest używana jako "podstawa" do tworzenia nowych baz. tzn. za każdym razem jak robisz: "create database xxx;" to tak naprawdę jest wykonywana kopia bazy template1.
daje to parę fajnych możliwości – np. zrobienie czegokolwiek w bazie template1 oznacza, że każda nowa baza będzie to miała automatycznie.
np. załadowane rozszerzenie, języki itd.
co jednak jeśli do template1 przez pomyłkę wrzuciliście jakieś zbędne dane? np. odtworzyliście do template1 zamiast do xxx jakąś bazę z dumpa?
ręczne kasowanie jest skomplikowane.
ideałem byłoby przywrócenie template1 do stanu początkowego.
da się to prosto zrobić.
w pierwszym kroku łączymy się psql'em do postgresa, na konto admina (zazwyczaj postgres, lub pgdba). ważne jest by połączyć się do bazy innej niż template1.
będąc tak połączonym wykonujemy 4 proste kroki:
- update pg_database set datistemplate = false where datname = ‘template1';
- drop DATABASE template1;
- CREATE DATABASE template1 with template template0;
- update pg_database set datistemplate = true where datname = ‘template1';
krok 1 jest niezbędny gdyż baza z wartością "datistemplate = true" nie może być skasowana. więc zaznaczamy, że template1 nie jest szablonem 🙂
krok 2 – kasujemy bazę template1. tu dwie ważne uwagi:
- w czasie wykonywania drop database do dropowaniej bazy nie może być żadnych połączeń. właśnie dlatego musieliśmy się psql'em podpiąć do innej bazy.
- między drop database template1, a create database template1 nie da sie stworzyć innych baz (a dokłaniej, nie jest to tak proste jak zazwyczaj)
krok 3 – odtwarzamy bazę template1, korzystając z szablonu template0
krok 4 – zaznaczamy template1 jako szablon.
i już to wszystko.
tu informacja dodatkowo. może to wykryliście z powyższego przykładu, ale jak nie, to piszę:
w podobny sposób można zrobić *szybką* kopię całej bazy.
np. jeśli potrzebujecie backup przed odpaleniem na bazie jakichś skomplikowanych rzeczy, można:
create database xxx_backup with template xxx;
oczywiście do tego przydałoby się też ‘encoding qqq owner yyy', ale to już szczegół.
olbrzymim plusem tej metody jest szybkość. przy czym nie szybkość tworzenia kopii. to czasem jest dłuższe niż pg_dump. to co jest istotne, to fakt iż "przywrócenie" bazy danych z takiej kopii, to proste:
drop database xxx;
alter database xxx_backup rename to xxx;
największym minusem jest fakt iż w czasie kopiowania do bazy źródłowej nie może być żadnych połączeń. czyli nie można tak skopiować bazy używanej produkcyjnie.
to spora wada. tym niemniej w środowiskach testowych/developerskich stosuję ją często z wyśmienitym skutkiem.
tapeta na dzis

deviantart
drzewa w sql’u – metoda “zagnieżdżonych zbiorów”
metodę zagnieżdżonych zbiorów poznałem po raz pierwszy po przeczytaniu którejś z książek joe celko. chyba tej: Advanced SQL Programming, ale na 100% nie jestem pewien.
zagnieżdżone zbiory (nested sets) polegają w duzym skrócie na tym, że każdy element drzewa jest opisany nie jednym id, ale parą liczb. są to w miarę dowolne liczby, z założeniem jedynie takim, że "lewa" jest mniejsza od "prawej", oraz, że obie liczby (lewa i prawa) wszystkich elementów drzewa poniżej danego muszą się mieścić w zakresie (lewa, prawa) swoich rodziców.
skomplikowane? też nie zrozumiałem.
przypomnijmy sobie nasze oryginalne, testowe drzewo:
teraz.
tworzymy sobie taką tabelkę:
# create table nested_sets ( id_left int4 primary key, id_right int4 not null check (id_left < id_right), name text);
jako primary key wybrałem sobie id_left, ale mogłem wybrać też right. w szczególności – wartości w polach id_left i id_right muszą być unikatowe. czyli jeśli w którymś elemencie w polu id_left jest wartość 5, to nie może się ona powtórzyć ani w id_left ani w id_right.
ok. jak nadać numerki?
proste. zaczynamy od elementu głównego, i przyznajemy mu id_left = 1. potem idziemy do jego pierwszego dziecka. jego id_left dajemy kolejny numer. jeśli ten element ma podelementy, to powtarzamy zejście w dół z przyznawaniem kolejnych id_left. jeśli dany element nie ma "dzieci", to nadajemy mu id_right równy kolejnej liczbie. i wracamy piętro wyżej.
mało jasne? pewnie nie umiem za dobrze opisać. więc lecimy w krokach:
- elementowi sql, przypisujemy id_left = 1, i schodzimy w dół do "postgresql".
- elementowi postgresql, przypisujemy id_left = 2, i ponieważ ma jakieś dzieci, schodzimy w dół – do "linux"
- elementowi linux przypisujemy id_left = 3
- ponieważ linux nie ma "dzieci", przypisujemy mu id_right = 4 i wracamy wyżej
- ponieważ postgresql nie ma "dzieci", przypisujemy mu kolejne id_right. czyli id_right = 5. i wracamy wyżej.
- jesteśmy z powrotem w sql. wchodzimy w kolejne dziecko – oracle
- elementowi oracle przypisujemy id_left = 6.
- itd. aż dojdziemy do ustawienia dla elementu sql, id_right = 18
zwracam uwagę na to, że w tej numeracji widać od razu, że ilość elementów jest równo połową największego id_right. co jest poniekąd logiczne.
cała tabelka wygląda tak:
| id_left | id_right | name |
| 1 | 18 | sql |
| 2 | 5 | postgresql |
| 3 | 4 | linux |
| 6 | 17 | oracle |
| 7 | 8 | solaris |
| 9 | 14 | linux |
| 10 | 11 | glibc1 |
| 12 | 13 | glibc2 |
| 15 | 16 | windows |
ok. jak się pyta taką bazę?
tu uwaga – ten model znam najsłabiej. głównie dlatego, że go osobiście nie lubię. jeśli znajdziecie błąd w tym co poniżej napiszę – proszę o informację. nie jestem nieomylny, a jak już mówiłem – tego modelu drzew nie lubię i nie bawiłem się nim w ogóle.
1. pobranie listy elementów głównych (top-levelowych)
SELECT
ns1.*
FROM
nested_sets ns1
LEFT OUTER JOIN nested_sets ns2 ON (ns1.id_left > ns2.id_left AND ns1.id_right < ns2.id_right)
WHERE
ns2.id_left IS NULL
;
zwrócić należy uwagę na fakt iż jeśli nasze drzewo ma tylko i wyłącznie 1 element top-levelowy to zapytanie można uprościć do:
# SELECT * FROM nested_sets WHERE id_left = 1;
jeśli stosujemy numerację od 1, lub
# SELECT * FROM nested_sets ORDER BY id_left ASC LIMIT 1;
jeśli numeracja startuje od nieznanej liczby.
2. pobranie elementu bezpośrednio “nad” podanym elementem:
dane wejściowe:
- ID : id_left elementu
SELECT
ns.*
FROM
nested_sets ns
WHERE
[ID] BETWEEN ns.id_left + 1 AND ns.id_right
ORDER BY ns.id_left DESC LIMIT 1
jeśli zapytanie nic nie zwróci – znaczy to, że dany element był “top-levelowy”.
3. pobranie listy elementów bezpośrednio “pod” podanym elementem
dane wejściowe:
- ID : id elementu
SELECT
nsc.*
FROM
nested_sets nsp
JOIN nested_sets nsc ON (nsc.id_left BETWEEN nsp.id_left + 1 AND nsp.id_right)
WHERE
nsp.id_left = [ID]
AND NOT EXISTS (
SELECT *
FROM nested_sets ns
WHERE
( ns.id_left BETWEEN nsp.id_left + 1 AND nsp.id_right )
AND
( nsc.id_left BETWEEN ns.id_left + 1 AND ns.id_right )
)
4. pobranie listy wszystkich elementów “nad” danym elementem (wylosowanym)
dane wejściowe:
- ID : id elementu
SELECT
ns.*
FROM
nested_sets ns
WHERE
[ID] BETWEEN ns.id_left + 1 AND ns.id_right
5. pobranie listy wszystkich elementów “pod” danym elementem (wylosowanym)
dane wejściowe:
- ID : id elementu
SELECT
nsc.*
FROM
nested_sets nsp
JOIN nested_sets nsc ON nsc.id_left BETWEEN nsp.id_left + 1 AND nsp.id_right
WHERE
nsp.id_left = 6
6. sprawdzenie czy dany element jest “liściem” (czy ma pod-elementy)
dane wejściowe:
- ID : id elementu
>SELECT true from nested_sets WHERE id_left = [ID] AND id_right = [ID] + 1;
jeśli zwróci true – to jest liść. jeśli nic nie zwróci – to nie jest liściem.
7. pobranie głównego elementu w tej gałęzi drzewa w której znajduje się dany (wylosowany) element
- ID : id elementu
SELECT
ns.*
FROM
nested_sets ns
WHERE
[ID] BETWEEN ns.id_left + 1 AND ns.id_right
ORDER BY
ns.id_left ASC LIMIT 1
podstawową zaletą tego rozwiązania jest to, że bardzo szybko zwraca listę wszystkiego "nad", "pod" czy listę liści.
wadami jest mała intuicyjność, skomplikowane przenoszenie elementów (gdybym miał to zaimplementować, to najprawdopodobniej po prostu po każdym przeniesieniu od nowa bym numerował id_left/id_right.
dodatkowo – część zapytań wymaga albo "order by xxx limit 1", albo subselectów co raczej nie wróży dobrze wydajności. a order by limit 1 nie zawsze można użyć (np. użycie tego w joinach jest już mocno problematyczne).