all of you know copy command. it's fast for inserting new data. but can it be used it we want to insert or update rows?
sure, it will be more than one command, but it's perfectly doable. here's how.
all of you know copy command. it's fast for inserting new data. but can it be used it we want to insert or update rows?
sure, it will be more than one command, but it's perfectly doable. here's how.
cortilap @ freenode's #postgresql asked about how to create a check() that will allow only one of the columns to be not null.
it doesn't sound cool, let's see:
with 2 columns (a,b) you make a check: check ( (a is not null and b is null) or (a is null and b is not null) or (a is null and b is null))
whoa. and what about 3 columns? 4?
of course it creates some questions about the schema, but is there a way to do it? without such long checks?
one solution is to make a function to check it. but perhaps a simpler solution is possible?
luckily all of the fields are ints.
a quick think, and here we go:
check (coalesce(a*0, 1) + coalesce(b*0, 1) + coalesce(c*0, 1) > 1)
and what is the field was text? same thing, but instead of doing “X"*0, i would do “length(X)*0" 🙂
[ wersja polska poniżej ]
just found this nice brain teaser.
i have this code in bash:
echo -e "1 1\n2 2" | while read A B; do echo "[$A] [$B]"; echo "ZZZ"; done
it will print:
[1] [1] ZZZ [2] [2] ZZZ
which is perfectly valid and sensible.
but if i'll change the command to:
echo -e "1 1\n2 2" | while read A B; do echo "[$A] [$B]"; ssh localhost date; echo "ZZZ"; done
i.e. i added ‘ssh localhost date' which connect to localhost over ssh, logins to my own account, and issues “date" command (can be any command), it shows only:
[1] [1] Tue Sep 18 15:45:24 CEST 2007 ZZZ
and finishes work. (i have a password-less login in localhost, so it doesn't ask for password).
and the question is: why there is no second step of while loop?
( side note: i know the answer, it's just a riddle for you 🙂
trafiłem właśnie na niezłą łamigłówkę:
poniższa linijka w bashu:
echo -e "1 1\n2 2" | while read A B; do echo "[$A] [$B]"; echo "ZZZ"; done
wypisze:
[1] [1] ZZZ [2] [2] ZZZ
co jest w pełni sensowe i oczekiwane.
ale jeśli zmienię ją na:
echo -e "1 1\n2 2" | while read A B; do echo "[$A] [$B]"; ssh localhost date; echo "ZZZ"; done
tzn. dodam ‘ssh localhost date', co łączy się na moje konto na localhoście i wykonuje polecenie “date" (może to być dowolne polecenie), wynikiem całości jest tylko:
[1] [1] Tue Sep 18 15:45:24 CEST 2007 ZZZ
i to koniec (mam logowanie bezhasłowe więc nie ma prośby o hasło).
pytanie: czemu nie ma drugiego wykonania kodu w pętli while?
( oczywiście (jak przy poprzednich łamigłówkach) znam odpowiedź ).
this questions pops every once in a while on irc.
some guy has a table, and it contains duplicated rows.
basically there are 2 possible scenarios:
so, how to remove duplicates from such tables?
this topic has been written about by many smart people – from the recent past, by greg sabino mullane and josh berkus.
they show 4 different approaches:
all these approaches have their benefits and drawbacks, but i'd like to show another one (polish readers saw the approach already in january 2007, but this time i will make the code more robust).
as most of you know postgresql can easily speedup searches using:
field like 'something%'
and (less easily):
field like '%something'
but how about:
field like '%something%'
general idea is to use some kind of full text search/indexing – tsearch, lucene, sphinx, you name it.
but sometimes you can't install fts/fti, or it doesn't really solve your problem. is there any help? let's find out.
so there you go, you have some “categories" and some objects. for simplicity let's assume one object can be in only one category.
if this is too theoretical for you – let's assume these are “mails in folders", “photos in galleries", “posts in categories" or “auctions in categories on ebay".
everything clear? now, let's assume you want to know how many “objects" are in given “category".
most basic way to do it is:
select count(*) from objects where category = some_category;
but this method is far from optimal. now, we'll learn how to do it better.
one warning for those of you who read the rss feed – if you say “yeah, i know the code, it's simple" – ask yourself – is your code deadlock-proof?
Continue reading objects in categories – counters with triggers
new commit info from cvs:
Log Message: ----------- Stamp releases 8.2.5, 8.1.10, 8.0.14, 7.4.18, 7.3.20.
it doesn't mean that we will see them today, but it means that we should be getting them really soon now 🙂 (at least that's what i hope)
znajomy zadzwonił i poprosił bym mu nagrał jakiś serial w tv.
nagrałem i w trakcje oglądania spojrzałem na reklamy. pojawiła się reklama “vision express" gdzie dają zniżki procentowo takie ile ma się lat.
reklama jak reklama, ale to co mnie całkiem powaliło to wygląd tej planszy do sprawdzania wzroku (litery różnej wielkości).
oto 2 “screenshoty" z tej reklamy:
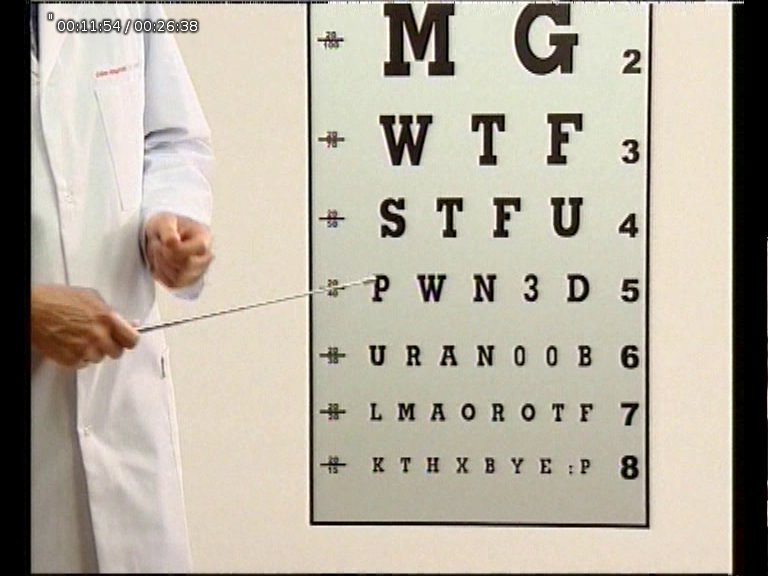
drugie zdjęcie jest nieostre (kamera w reklamie była w ruchu), ale pokazuję, że na górze jest “O".
powstaje pytanie – czy ten co zatwierdzał reklamę zwrócił uwagę na żarcik? z treści reklamy nie wynika by miała być ona “z przymrużeniem oka".
just recently i saw a very interesting situation.
one table in customer database (with about 1.5 milion rows) was *very often* updated. using series of simple:
update table set field = .., where id = ...
updates always updated 1 record, search was using primary key, so it was quite fast.
what was strange was the fact that the table get about 20 times more updates then the next most updated table.
after careful checking i found out that a lot (about 60-70%) of the updates actually didn't change anything!
they were simply setting values that were already there.
so, i started to think about hwo to avoid this kind of situation.
and this is what i found out.