jak może wiecie w postgresie jest funkcja currval() zwracająca ostatnio nadane id z podanej sekwencji.
rozpatrzmy prosty przypadek:
# create table test (id serial primary key, pole int4); CREATE TABLE # insert into test (pole) select * from generate_series(1, 10000); INSERT 0 10000 # select count(*) from test; count ------- 10000 (1 row) # select currval('test_id_seq'); currval --------- 10000 (1 row)
wszystko wygląda ok. więc sprawdźmy jeszcze jeden insert mały:
# insert into test(pole) values (12313); INSERT 0 1 # select currval('test_id_seq'); currval --------- 10001 (1 row)
nadal wszystko ok. i teraz:
# select * from test where id = currval('test_id_seq'); id | pole -------+------- 10001 | 12313 (1 row) Time: 93.358 ms
działa, ale coś wolno, sprawdźmy:
# explain analyze select * from test where id = currval('test_id_seq'); QUERY PLAN -------------------------------------------------------------------------------------------------- Seq Scan on test (cost=0.00..200.02 rows=1 width=8) (actual time=64.375..64.379 rows=1 loops=1) Filter: (id = currval('test_id_seq'::regclass)) Total runtime: 64.431 ms (3 rows)
seq scan? sprawdźmy więc ręcznie podaną wartość:
# explain analyze select * from test where id = 10001; QUERY PLAN ---------------------------------------------------------------------------------------------------------------- Index Scan using test_pkey on test (cost=0.00..8.02 rows=1 width=8) (actual time=0.029..0.033 rows=1 loops=1) Index Cond: (id = 10001) Total runtime: 0.086 ms (3 rows)
hmm .. tu jest dobrze. skąd seq scan? aby nie przynudzać z każdym zapytaniem, powiem tyle, że nie jest to kwestia błędnych typów czy czegoś tak oczywistego. problemem jest zmienność funkcji.
dokładniej: funkcja currval() jest zadeklarowana jako “volatile" – co oznacza, że jej wynik ma prawo zmienić się w czasie pojedynczego skanu tabeli. tak jak np. random(). to oznacza, że nie można użyć jej jako dostarczyciela wartości i potem tą wartością przeszukać indeksy.
cóż więc można zrobić – no cóż. trzeba powiedzieć postgresowi, że interesuje nas tylko pierwsza zwrócona wartość currvala – idealnie do tego nadają się podzapytania:
# explain analyze select * from test where id = (select currval('test_id_seq')); QUERY PLAN ---------------------------------------------------------------------------------------------------------------- Index Scan using test_pkey on test (cost=0.01..8.03 rows=1 width=8) (actual time=0.047..0.050 rows=1 loops=1) Index Cond: (id = $0) InitPlan -> Result (cost=0.00..0.01 rows=1 width=0) (actual time=0.010..0.012 rows=1 loops=1) Total runtime: 0.187 ms (5 rows)
jak widać jest już zdecydowanie lepiej.
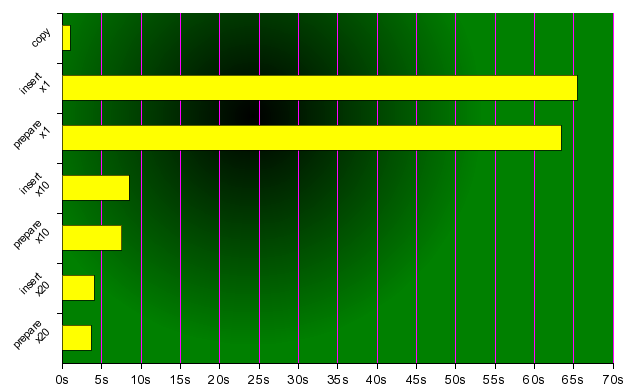 jak widac przyspieszenie insertów jest znaczne. czy to wszystko? nie!
jak widac przyspieszenie insertów jest znaczne. czy to wszystko? nie!