na razie tylko link do informacji. jutro postaram się zrobić pełen opis zmian z uwzględnieniem tego co w/g mnie najważniejsze.
Tag: postgresql
postgres 8.2 ?!
najnowsza wersja postgresa z cvs'u ma wersję … 8.3devel!
w cvs'ie powstały branche REL8_2_0 i REL8_2_STABLE.
na webie jeszcze nie obwieścili nowiny – jak tylko to zrobią dam znać i opiszę co się zmieniło.
oczywiście jest też szansa, że do wypuszczenia jeszcze dużo czasu, a head ma wersję 8.3devel bo pojawiły się patche wykraczające poza 8.2 🙂
dlaczego lubię postgresa
niesamowita prędkość, super sql. to wszystko nic nie znaczy gdy baza po prostu nie działa. a błędy zdarzają się przecież wszystkim.
co wtedy ma znaczenie? support.
wczoraj natknąłem się na krytyczny błąd w postgresie 8.2 rc1. i co dalej? timeline:
- 11:38 – wysyłam na pgsql-general informacje o błędzie, core'a, log oraz konfigi
- 12:16 – dostaję informację by cośtam jeszcze podesłać
- 12:33 – podsyłam
- 12:54 – prośba o binarkę postgresa
- 14:16 – wysyłam ją (nie było mnie godzinę przy biurku)
- 16:03 – włącza się tom lane podpowiadając jakiś szczegół
- 16:06 – potwierdzenie, że błąd zreplikowany u developera
- 17:25 – dostaję informację, że bug poprawiony, zmiany zacommitowane i dodatkowo podziękowania za zgłoszenie błędu
łącznie – niecałe 6 godzin! (w tym godzina spowolnienia przez moją nieobecność).
z tego co słyszę to reakcja na błędy w bazach komercyjnych jest liczona w dniach albo tygodniach. a nie godzinach.
aha. poprawka oczywiście działa.
ciekawy benchmark
serwis tweakers.net zajmuje się benchmarkowaniem różnych rzeczy – m.in. serwerów. im zawdzięczam swoją fascynację kontrolerami raid areca, im zawdzięczam kilka innych ciekawostek jakich się dowiedziałem.
ostatnio przeprowadzili benchmark nowego serwera – maszyny dell power edge 1950, z nowymi procesorami intela i kupą innych zabawek.
maszyna oczywiście wypadła super.
ale nie o to mi chodzi.
jednym z przeprowadzonych testów była wydajność i skalowalność ich własnego serwisu (kopii) postawionego na testowanej maszynie.
testy te przeprowadzali na mysql'u 4.1.20, 5.0.20a, oraz snapshotcie postgresa 8.2 prosto z cvs'u 🙂
wyniki?
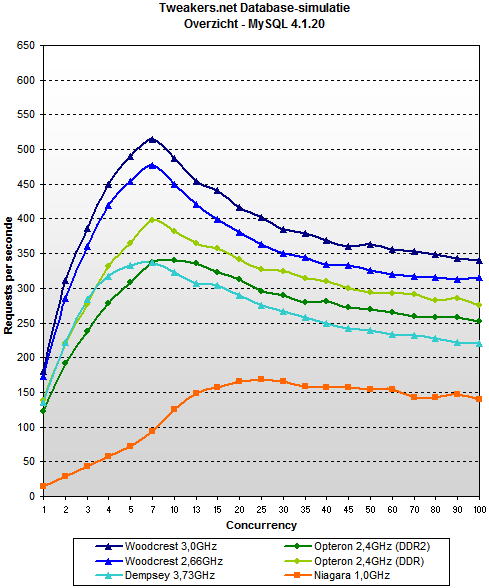
tak wygląda wykres (przypominam, te wykresy porównują zachowanie systemu na jednej bazie na wielu różnych maszynach) od mysql'a 4.1:
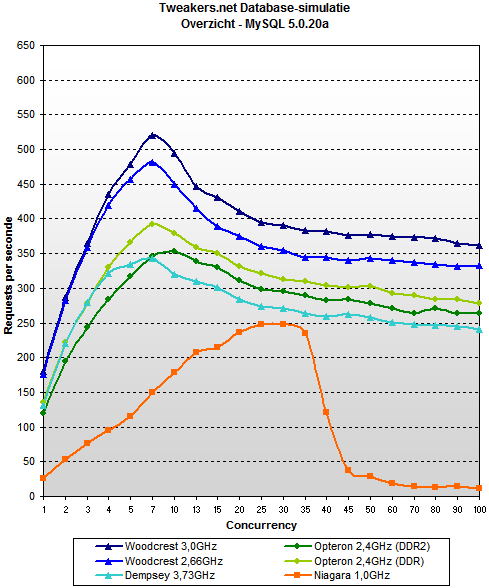
a tak od mysql'a 5.0:
to teraz wykres dla postgresa:
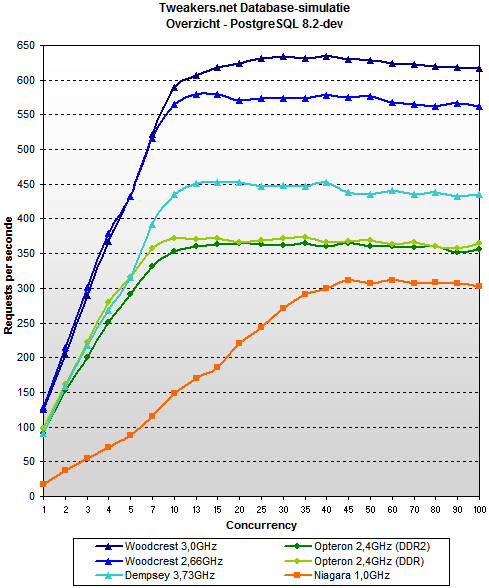
na wypadek jeśli nie łapiecie o co mi chodzi – nie, nie chodzi mi wcale o to, że postgres robi więcej requestów na sekundę – to kwestia wtórna, optymalizowalna i łatwo fałszowalna.
to co mnie w mysql'u boli to to, że w pewnym momencie, wraz ze wzrostem ilości klientów prędkość obsługi dramatycznie spada. oczywiście najlepiej to widać na niagarze przy mysql 5.0, ale na każdym serwerze mysql ma tendencje spadkowe po osiągnięciu około 10 jednoczesnych zapytań. postgres natomiast nie.
oczywiście – tweakersi mogli zafałszować dane. true. ale ten schemat zachowania przewijał mi się wiele razy gdy czytałem o mysql'u. i chyba dlatego jakoś nigdy nie mogłem tej bazy polubić.
tuningowanie aplikacji bazodanowych korzystających z postgresa – kontynuacja
tak jak już d- mi zauważył pojawiła się druga część podpowiedzi nt. tunintowania aplikacji – napisana oczywiście przez josha berkusa.
w tej części podpowiedzi:
- delete jest kosztowny
- używanie prepare/execute dla wywoływania zapytań w pętli
- używanie connection-pool'i (buforów połączeń?)
BUG w postgresie :)
heh
wykryłem pierwszego poważnego buga w postgresie 🙂
w 8.2rc1 jest bug który wykłada postgresa (segfault, sig 11) przy vacuumowaniu indeksów gin 🙂
w sumie szkoda – bo giny są niesamowicie szybkie – ale i dobrze, bo bug namierzony to bug zniszczony. i mogę się chwalić, że przyczyniłem się do poprawienia stabilności postgresa 🙂
tuningowanie aplikacji bazodanowych korzystających z postgresa
josh berkus, osoba dosyć znana w światku postgresowym, opublikował na swoim blogu pierwszy (z serii?) wpis nt. tuningowania aplikacji.
wpis zawiera wstęp teoretyczny i 3 hinty.
hinty sa proste:
- nigdy nie używaj wielu małych zapytań gdy jedno większe załatwiłoby sprawę.
- grupuj wielokrotne insert/update/delete w pojedyńcze operujące na większej ilości danych, lub gdy sie nie uda – w transakcje.
- rozważ zastosowanie bulk-loadingu (copy) zamiast serii insertów.
wstęp teoretyczny jest także istotny, ale ani tego ani dokładnego uzasadnienia hintów tłumaczyć nie będę – przeczytajcie sami.
chore skojarzenia google’a :)
w postgresie jest coś takiego jak tsearch – silnik do wyszukiwania pełnotekstowego.
jednym z elementów silników pełnotekstowych jest stemmer – soft który zamienia słowa na ich wersje podstawowe – np. “depeszowi" na “depesz".
stemmerem którego użycie ludzie od tsearcha polecają jest snowball. zasadniczo nie jest to nawet stemmer, tylko specjalizowany język programowania do pisania stemmerów. kompilowanych potem do kodu w c.
niestety – nie ma stemmera snowballowego dla języka polskiego. jest rosyjski, angielski węgierski i kilka(naście) innych. polskiego brak.
niezrażony poszukałem na google‘ach. i co znalazłem na pierwszym miejscu? aaargh. 🙂
postgresql 8.2 rc1!
właśnie (dziś w nocy) źródła w cvs'ie postgresa zostały otagowane jako rc1! czyli wyjście 8.2 jest już nie tyle na horyzoncie, co już tuż-tuż za rogatkami 🙂
kluster postgresów na płytkach?
austriacka firma cybertec zaoferowała nowy produkt: “out of the box cluster".
w założeniach jest to zestaw oprogramowania który po instalacji na serwerach daje gotowy, skonfigurowany klaster bazodanowy.
funkcje:
- replikacja multi-master (nie wiem jeszcze czy jest to replikowanie zapytań czy danych, wysłałem zapytanie, zobaczymy co powiedzą)
- pełna obsługa 2-fazowych commitów (to jest interesujące – może wreszcie zrobili replikację danych przy użyciu tej technologii?)
- rozszerzone funkcje monitorujące poprzez dedykowany serwer
- automat sprawdzający spójność bazy danych
- pełny support 24/7
- po instalacji na serwerze jest zasadniczo debian (jak rozumiem jest to ubuntu dapper, wersja serwerowa)
- system jest gotowy do użytku od razu po instalacji
ceny – całkiem sensowne – wersja na 3 node'y już od 2000 euro. jak coś będę wiedział więcej – napiszę.