jeden z klientów eo, firmy gdzie pracuję, właśnie kupił nowy serwer pod bazy danych. ponieważ maszynkę trzeba przetestować, stwierdziłem, że przy okazji porównam sobie jej wydajność z innym serwerem – nieużywanym już starszym serwerem bazodanowym.
poprzednia maszynka:
- 2 procesory amd opteron 250, 2.4ghz
- 4 giga ramu
- 4 dyski scsi, 15krpm, spięte sprzętowym raidem w dwie macierze raid1 po dwa dyski.
- postawiona pod centosem z kernelem 2.6.9-22.ELsmp
czyli tak naprawdę bez przesadnych rewelacji.
testowałem przy pomocy takiego skryptu:
#!/bin/bash export TOTAL_TRANS=1000000 for C in 1 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 do pg_ctl -w -l logs/x.log start dropdb bench createdb bench pgbench -i -s 750 -U pgdba -d bench TRANS=$[ $TOTAL_TRANS / $C ] pgbench -s 750 -c $C -t $TRANS -U pgdba -d bench 2> /dev/null > /home/pgdba/bench-$CC-$C.std pg_ctl -m immediate stop killall -9 postgres killall -9 postmaster killall -9 postgres killall -9 postmaster done
proste i konkretne. baza bench ma około 13 giga (aha. gdybyście chcieli powtórzyć test u siebie – pgbench się wywala na -s 750 (na niższych trochę pewnie też) i trzeba go zapatchować – w pgbench.c znaleźć polecenia tworzenia tabel i zastąpić inty bigintami.
postgresql'a użyłem 8.1.4, postgresql.conf zawierał wartości domyślne, zmieniłem jedynie 2 parametry:
max_connections = 110 shared_buffers = 65536 lc_messages = 'en_US.UTF-8' lc_monetary = 'en_US.UTF-8' lc_numeric = 'en_US.UTF-8' lc_time = 'en_US.UTF-8'
czyli jak widać nic specjalnego – chodziło mi nie o tuning postgresa, tylko o sprawdzenie o ile mi mniej więcej przyspieszy system po zmianie sprzętu.
wyniki starszego serwera:
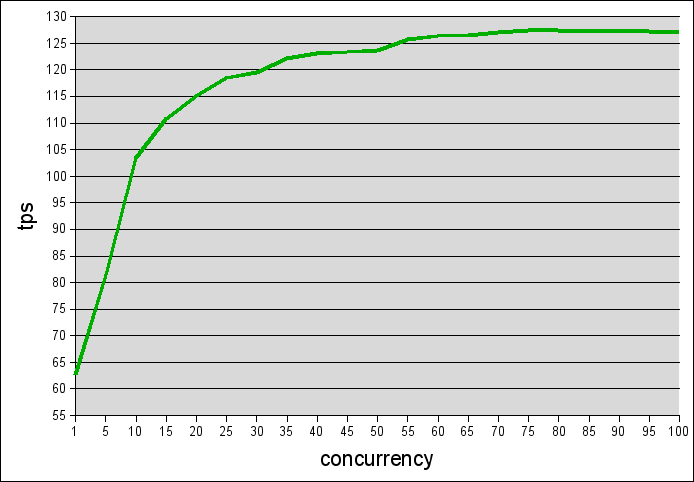
rzuca się w oczy stabilność wydajności przy przyroście jednocześnie połączonych klientów.
nowa maszynka:
- 4 procesory amd opteron 875, 2.2ghz
- 32 giga ramu
- 2 dyski sas na system, 14 dysków w zewnętrzen macierzy scsi, 15krpm, spięte w jedną dużą macierz raid10
- postawiona pod debinanem testing z kernelem 2.6.16-2-amd64-k8-smp
test i konfiguracja postgresa – identyczne.
wyniki:
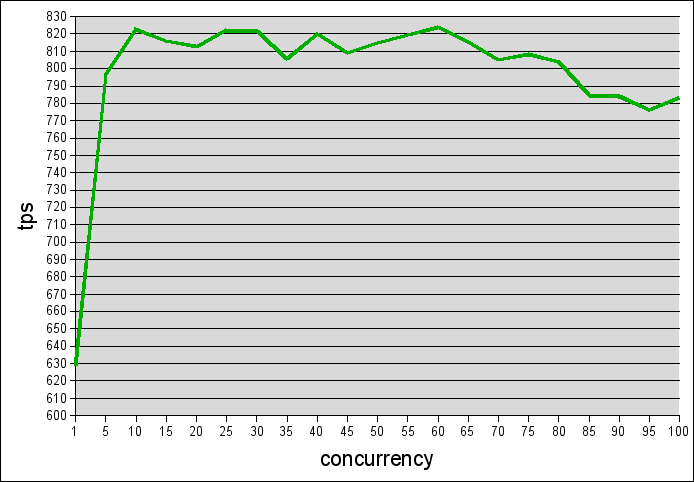
tym razem rzuca się w oczy brak stabilności wyników przy większej ilości połączeń.
ale też liczby są sporo wyższe 🙂 ponad 6 krotnie wyższe.
zakładam, że brak stabilności może wynikać z tego, że dla tej maszyny ta baza była mała. tzn. baza mająca 13 giga dla maszyny z 4giga ramu to sporo. ale dla maszyny z 32 giga ramu, to drobiazg.
zrobię jeszcze jeden test (będzie dłuższy, więc wyniki pewnie dopiero w poniedziałek) – dokonfiguruję postgresa do końca, i zrobię test na bazie danych tak ze 110 – 120 giga. postaram się zrobić testy do większej ilości klientów.
może to wyjaśni przyczynę dziwnych wahań wyników.
aha – testy nie są idealne – pgbench ma swoje standardowe problemy. dodatkowo – ta maszyna, co prawda nie jest używana normalnie, ale chodzi na niej cron który np. w nocy włącza “updatedb" to pewnie trochę zaburza wyniki.
jeszcze tylko muszę się dowiedzieć ile te maszynki kosztowały aby móc porównać “bang-for-bucks" 🙂